建立在大数据背景之下当然,要解释清楚什么是Hadoop那得要从大数据说起。 在20多年前,也就是上个世纪90年代,数据大量产生(也并不是之前没有这么多数据,而是由于科学技术的原因,这些日常生活中的数据转瞬即逝并没有被人们记录下来),这个“大量产生”有多么夸张呢,现在的数据量相当于之前数据量的上百上千倍! 数据如此快速地增长势必带来一些问题,我们先来做一道小学3年级的应用题,请听题:90年代的数据量相当于10个零件,一个小朋友1分钟走一趟搬1个零件,花10分钟可以搬走这些零件;90年代以后的数据量相当于10000个零件,这个小朋友也长大了,他1分钟走一趟可以搬4个零件,那么要搬走这些零件要花多长时间呢? 答案是2500分钟! 也就是说,数据读取技术的发展完全跟不上数据量的增长速度啦!于是聪明的我们就用到了分布式——是整个Hadoop的核心思路。 运用分布式解决单体能力有限的问题。什么是分布式?一个很浅显的道理,我们完全没必要培养一个1分钟能搬100个人零件的壮汉,那也不太现实1个人搬零件搬得太慢我们可以请10个人呀,再不行就请100个人、1000个人,这就是所谓的分布式。 但随着零件数的增加问题,如何处理好这么多零件呢? Hadoop核心设计:HDFS和MapReduce我们首先要分配好这些零件。大数据时代我们面临的是以TB、PB甚至EB为单位的数据,因此,我们需要建立一个既能存的下如此大量的数据,而且还能高速高效地读写文件的文件管理系统——HDFS。HDFS也就是Hadoop分布式文件系统,将一份巨型的文件分散到多台存储设备中,并配合一个调度程序来管理这些文件。 那么HDFS是如何运作的呢?先听个故事某零件厂的老板(客户Client)手里有一大批零件要存放。然而一个单独的仓库根本无法存放如此之多的零件。于是老板想到了建立一个仓库集群(HDFS),把自己的零件分批存放在不同的仓库(主机host)里,再建立一个覆盖所有仓库的管理系统。 老板现将这批零件分装成小包,每个小包都可以放进任意一个仓库,小包的存放信息会被包工头记录下来。 包工头(NameNode)是整个仓库的监视者也是分配者,他监视这仓库集群里所有的仓库和仓库里的奴隶(DataNode)。当他收到老板的命令之后,他会现将老板提供的所有小包的信息和存放位置记录下来,然后看一眼哪些仓库里有空闲的奴隶(DataNode)可以去保管。包工头一直监视着各个仓房的状态和奴隶们的状态,他通过感受奴隶们是否还有心跳(heartbeat)来判断奴隶是否还活着。一旦某个看管货物的奴隶死了,包工头就会命令同仓房一个空闲的活着的奴隶去顶替他的位置。 具体的流程图是这样的: 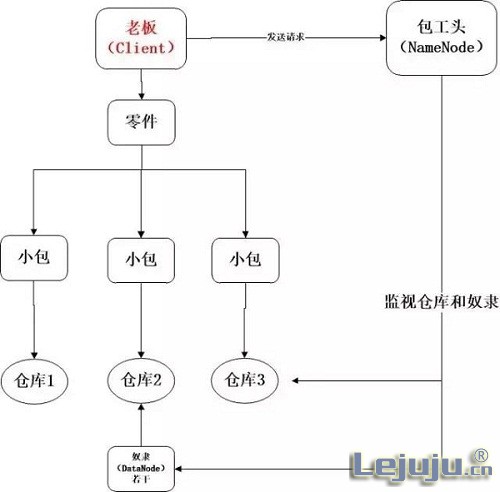 当文件都通过HDFS存放好之后,我们就要考虑如何来利用这些数据了。人们常常通过数据之间的关联来挖掘出数据中的潜在价值,而杂乱无章的数据会对数据挖掘产生很大的阻碍。这时候就需要建立一个编程模型来对数据进行排序整理,这就是Hadoop的另一个核心——Mapreduce。 我们再来看另外一个故事:依旧还是那个零件厂老板,一天他突然要求,将他所有的零件全部按种类统计数量。老板采取了以下措施: 1.雇佣管理员和大量的清点员。 2.管理员指挥清点员去把每个小包都拆开然后清点每个小包中包含的零件和个数,例如:清点员1清点小包1:零件A,1个;零件B,2个;零件C,1个;零件D,2个。清点员2清点小包2:零件A ……(这就是Map) 3.雇佣整理员整理员1只负责整理零件A和零件B的数量整理员2只负责整理零件C和零件D的数量…… 4.清点员们向整理员汇报。例如:清点员1向整理员1汇报小包1里有A,1个;B,2个向整理员2汇报小包1里有C,1个;D,2个然后清点员2汇报…… 5.整理员把自己收到的信息汇总,例如:整理员1总共有A,n个,总共有B,m个;整理员2说……(Reduce) 总体说来,HDFS是Hadoop的储存基础,是数据层面的,提供储存海量数据的方法(分布式储存)。而MapReduce,是一种引擎或是一种编程模型,可以理解为数据的上一层,我们可以通过编写MapReduce程序对HDFS中海量的数据进行计算处理(分布统计整合)。这就类似于我们通过MapReduce(读取)所有文件(HDFS)并进行统计,从而找到我们想要的结果。所以说Hadoop是一种能帮助我们大量储存数据并且能处理数据的工具。 (好像又很多名词了........) 其实HDFS和MapReduce仅仅只是Hadoop最基础的部分(其余的我们会在后续的文章中慢慢提到)。Hadoop从2006年诞生至今的十年里,已经经历了数次更新,更是开发出了多种延伸功能。各种以Hadoop为基础开发产品的公司早已遍布世界各地,各种Hadoop技术应用的案例也是数不胜数。所以小编想告诉大家:不要将Hadoop想象得遥不可及,Hadoop早已成为我们生活的一部分。 |





 我也要投稿
我也要投稿




香港服务器多少钱一个月?哪家的香港服务器
4核4g6M50G盘20G防御云服务器价格多少钱?T